Context Free Languages
This is a methodology for representing languages. It is more powerful than DFAs and RE, but is still not enough to define all the possible languages. The basic idea is to use “variables” as stand-ins for sets of strings.
Formally, the terms described below define a CFG.
\[G = (V,\Sigma, R,S)\]- Terminals ($V$)- The symbols of the alphabet
- Variables / Non terminals ($\Sigma$) - A finite set of other symbols
- Start Symbol ($S$)- The variable whose language is being defined
- Production ($R$)- A rule of the form “$\text{variable} \rightarrow \text{variables} ∪ \text{terminals}$“
“Productions of A” refers to the set of all strings that are derivable from $A$ using the rules defined by the CFG. A string $\gamma$ is said to be derived from $\alpha$ iff the application of a rule results in $\gamma$. This is represented as $\alpha\implies\gamma$.
Derivation using 0 or more steps is represented by $\overset{*}{\implies}$.
Any string derived from the start string is called as a Sentential Form. It essentially is a string “on its way” to becoming part of the language.
A language defined by a CFG is called as a Context Free Language.
BNF Notation (Backus-Naur-Form)
This is a method of representing the rules of CFG in a programming way.
| CFG Part | BNF Representation | Example |
|---|---|---|
| Variable | <word> | <state> |
| Terminals | multicharacter strings in bold or underlined | while, while, while |
| $\rightarrow$ in rule definitions | $::=$ | <state> ::= a |
| “or” in rule definitions | $\vert$ | <state> ::= a$\vert$b |
| (not) Kleene Closure ($a^+$) | “…” | <state> ::= <\state>… |
| Optional Elements | […] | <state> ::= <statea> [or <stateb>] |
| Grouping $(ab)^*$ | {…} | <state> :== {<statea><stateb>}… |
Leftmost and Rightmost derivations
A problem with CFGs is that every word may have more than one derivations possible. This makes verification and confirmation difficult. A derivation is said to be “Leftmost” when only the leftmost non-terminal is operated on in every step of the derivation. The same definition works for rightmost derivations as well.
Parse Trees
Trees whose nodes are labeled by the symbols of a particular CFG. The leaves are labeled by terminals or $\epsilon$, Interior nodes by variables and the root by the start symbol.
The yield of a parse tree is given by concatenating the leaves in a left-to-right order. (The order of preorder traversal)
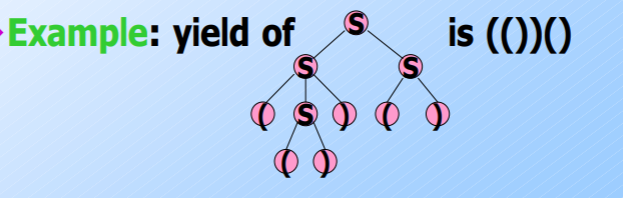
For every parse tree, there is a unique leftmost derivation. Conversely, for every leftmost derivation, there is a unique parse tree with the same yield.
The forward part can be proven using strong induction on the height of parse tree, and the backwards part can be proven using strong induction on the length of the derivation. Also, it can be seen from the proof that obtaining a parse tree doesn’t depend on the derivation being “leftmost”.
For any derivation, there exists a unique parse tree with the similar yield.
Ambiguous Grammar and LL(1) Grammar
Leftmost and Rightmost derivations had been introduced to alleviate confusions caused by multiple derivations. However, it is not guaranteed that a unique leftmost (or rightmost) derivation exists for a given string.
For example, consider grammar with the following rule. Two parse trees exist for the string “()()()”
\[S\rightarrow SS\vert (S)\vert ()\]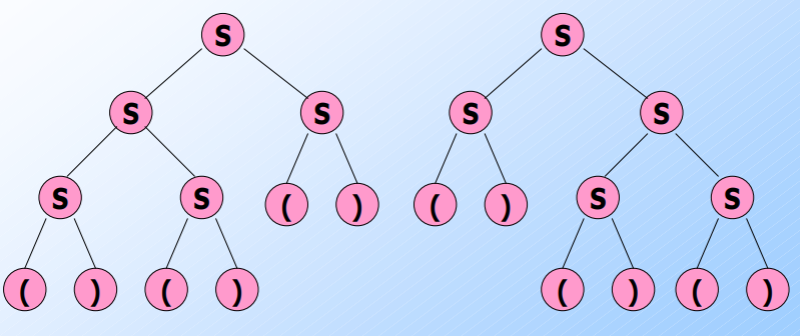
From the theorems discussed earlier, it can be concluded that two leftmost and rightmost derivations would exist for this grammar. This is thus called Ambiguous Grammar.
Note that ambiguity is a property of the grammar, and not the language itself. That is, we can write equivalent unambiguous grammar for the above example.
\[\begin{align*} B \rightarrow &(RB\vert\epsilon \\ R \rightarrow &)\vert (RR \end{align*}\]Grammar such as the above example, where we can figure out the production to use in a leftmost derivation by looking at the string left-to-right and looking at the next one symbol is called $LL(1)$ grammar. Leftmost derivation, Left-to-right scan, 1 symbol of lookahead.
$LL(1)$ grammars are never ambiguous.
Note that some languages are inherently ambiguous, meaning that there does not exist an unambiguous grammar that accepts the CFL’s language. For example, ${0^i1^j2^k\vert i=j\text{ or }j=k}$ is inherently ambiguous. This can be understood intuitively by looking at $0^n1^n2^n$, which could have been obtained from either the first check or the second check.
Eliminating Useless Symbols
Useless symbols are of two kinds:
- Symbols which do not derive a terminal string
- Symbols which are not reachable from the start
- Nullable Symbols
- Unit productions
We shall look at methods for elimination of such symbols.
Eliminating Symbols which do not derive a terminal string
Consider the following set of rules:
\[\begin{align*} S&\rightarrow AB \\ A&\rightarrow aA\vert a\\ B&\rightarrow AB \end{align*}\]It can be said that $S$ derives nothing and the language is empty. The algorithm for deducing this is quite simple and is based on induction.
Algorithm
Basis - If there is a production $A\rightarrow w$ where $w$ is composed of terminals, then $A$ derives a terminal string
Induction - If $A\rightarrow \alpha$ and $\alpha$ consists only of terminals and variables known to derive terminals, then $A$ derives a terminal string.
For a given set of rules, we perform the above induction and mark all the variables which generate a terminal string. We can then remove all the rules which include a variable which has not been marked.

Eliminating Unreachable Symbols
The symbols which are unreachable from the starting symbol are said to be unreachable. We can remove all rules which involve such strings as they are not relevant. The algorithm for removing unreachable symbols is similar to the algorithm for eliminating the symbols that do not derive a terminal string;
- Mark the start state, and iterate by marking all the variables that are derivable by the start state
- Rules involving unmarked variables can be eliminated
Epsilon Productions
A production of the form $A\rightarrow \epsilon$ is said to be an $\epsilon$-production.
If L is a CFL, then $L-{\epsilon}$ has a CFG with no $\epsilon$-productions.
A variable $A$ is said to be nullable when it can derive $\epsilon$ in a finite number of steps. That is, $A\overset{*}{\implies}\epsilon$. Eliminating nullable variables uses the same algorithm discussed earlier. Variables of form $N\rightarrow \epsilon$ are marked, and induction is performed. A variable $B\rightarrow\alpha$ is nullable iff all variables in $\alpha$ are nullable as well.
However, we cannot simply remove all rules which the nullable symbols are involved in. The following steps have to be followed:
- Remove all direct $\epsilon$ transitions ($N\rightarrow \epsilon$)
- Replace nullable variables on RHS of a rule with two cases, one unchanged and one with it being removed
Example:

Unit Productions
A production whose right side consists of exactly one variable is called a unit production. This is redundant and can be eliminated. That is, if $A\overset{*}{\implies}B$ by a set of unit productions and $B\rightarrow\alpha$ is a non-unit production; we can drop all the unit productions and just add $A\rightarrow\alpha$.
Chomsky Normal Form
Theorem
If $L$ is a CFL, there exists a CFG for $L-{\epsilon}$ that has:
- No useless symbols
- No $\epsilon$ productions
- No unit productions
A CFG is said to be in CNF iff every production in the grammar is one of these two forms:
- $A\rightarrow BC$ (RHS is two variables)
- $A\rightarrow a$ (RHS is a terminal)
Theorem
If $L$ is a CFL, there exists a CNF for $L-{\epsilon}$
Converting CFG to CNF
- “Clean” the grammar by removing the previously mentioned four kinds of “useless” variables
- For each of the rules where the RHS isn’t a terminal, convert the RHS to be all variables. For example, $A\rightarrow Ab$ can be written as $A\rightarrow AA_b, A_b\rightarrow b$.
- In right sides of length larger than 2, write them as a “chain” of rules. That is, consider $A\rightarrow BCD$. This can be rewritten as $A\rightarrow B E, E\rightarrow CD$.
Push Down Automata
PDA is defined by a 7-sized tuple:
\[(Q, \Sigma, \Gamma, \delta, q_0, Z_0, F)\]| Symbol | Meaning |
|---|---|
| $Q$ | States |
| $\Sigma$ | Input alphabet |
| $\Gamma$ | Stack alphabet |
| $\delta$ | Transition function |
| $q_0$ | Start state |
| $Z_0$ | Start symbol |
| $F$ | Set of final states |
The transition function takes three inputs; NFA state, input alphabet and the top of the stack and it outputs the resulting NFA state and the action to be performed on the stack. The actions available on the stack are either pushing multiple stack variables onto the stack, or popping the top of the stack.
Instantaneous Descriptions (ID) of a stack are given by the triplet mentioned above. Note that the stack variables are written in a top-first manner (top of the stack is at the left and the bottom is at the right).
$ID_1 \vdash ID_2$ is read as “ID1 goes to ID2”, and means that one transition rule has been applied. This can be extended to define $\vdash^*$ to mean application of zero or more transition rules.
Pumping Lemma for CFL
The statement of the pumping lemma is as follows.
For every context-free language $L$ there exists an integer $n$, such that for every string $z$ in $L$ such that $\vert z \vert\geq n$ it can be written as $z = uvwxy$ such that:
- $\vert vwx \vert \leq n$
- $vx>0$
- For all $i\geq 0, uv^iwx^iy\in L$
This extended pumping lemma can be used to prove that $L= { 0^i10^i10^i\vert i\geq 1 }$ is not CFL in nature.
Proof
Let $n$ be the corresponding constant for $L$. Consider the string $0^n10^n10^n$ which belongs to $L$. There are two cases for $v,x$.
- $v,x$ contain no $0$s. This implies that they contain at least one $1$, implying that $uv^iwx^iy$ has more than two $1$s and thus is not in the language.
- $v,x$ contains at least one $0$. Because $\vert vwx\vert \leq n$, it is too short to extend to all the three blocks, and is localized to the middle block. Therefore, $uv^iwx^iy$ would not have equal number of $0$s in all blocks and is thus not in the language as well.
Shown that $0^n10^n10^n$ is cannot satisfy Pumping Lemma in mutually exclusive and exhaustive cases. Therefore, $L$ is not a Context-Free Language and cannot be represented by a CFG.
Decision Properties of CFL
The same drill as what we had seen previously with regular languages. However, there exist many questions that were decidable for regular languages but are not for CFLs.
Are two CFLs the same?
Are two CFLs disjoint?
The above questions are decidable for regular languages, but there exists no algorithm in the case of context free languages.
Testing Emptiness
This is easy enough, we just eliminate all the variables which do not create a terminal string. If the start symbol is one such variable then the CFL is empty.
Testing Membership - CYK Algorithm
CYK algorithm runs in $\mathcal{O}(n^3)$ time, and uses dynamic programming, where $n=\vert w\vert$. We assume that the provided grammar is in CNF form. The working of the algorithm is given below.
- Construct a $n\times n$ triangular array, called $X$. $X_{ij} = {A\vert A\overset*\implies w_iw_{i+1}\ldots w_j }$ That is, it contains the set of all variables that derive this substring.
- The basis would be filling up all $X_{ii}$ with the variables that can generate that letter.
- Induction: $X_{ij}={A\vert \exists A\rightarrow BC, k\text{ where } i\leq k<j\text{ such that } B\text{ is in }X_{ik}\text{ and }C\text{ is in}X_{k+1,j}}$
- After induction, check if $S\in X_{1n}$

Testing Infiniteness
This is quite similar to the idea for regular languages. If there exists a string in $L$ of length in between $n$ and $2n-1$, then the language is infinite; otherwise not.
Closure Properties of CFL
Note that CFLs are closed under union, concatenation and the Kleene closure. Moreover, they are closed under reversal, homomorphism and inverse homomorphisms.
However, CFLs are NOT closed under intersection, difference and complement!